梯度下降法
梯度下降法(英语:Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。
要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
目录
1 描述
1.1 例子
1.2 缺点
2 参阅
3 参考文献
4 外部链接
描述

梯度下降法的描述。
梯度下降方法基于以下的观察:如果实值函数F(x){displaystyle F(mathbf {x} )}在点a{displaystyle mathbf {a} }处可微且有定义,那么函数F(x){displaystyle F(mathbf {x} )}在a{displaystyle mathbf {a} }点沿着梯度相反的方向 −∇F(a){displaystyle -nabla F(mathbf {a} )} 下降最快。



因而,如果
- b=a−γ∇F(a){displaystyle mathbf {b} =mathbf {a} -gamma nabla F(mathbf {a} )}

对于γ>0{displaystyle gamma >0}為一個够小数值時成立,那么F(a)≥F(b){displaystyle F(mathbf {a} )geq F(mathbf {b} )}。


考虑到这一点,我们可以从函数F{displaystyle F}的局部极小值的初始估计x0{displaystyle mathbf {x} _{0}}出发,并考虑如下序列
x0,x1,x2,…{displaystyle mathbf {x} _{0},mathbf {x} _{1},mathbf {x} _{2},dots }使得



xn+1=xn−γn∇F(xn), n≥0{displaystyle mathbf {x} _{n+1}=mathbf {x} _{n}-gamma _{n}nabla F(mathbf {x} _{n}), ngeq 0}。

因此可得到
- F(x0)≥F(x1)≥F(x2)≥⋯,{displaystyle F(mathbf {x} _{0})geq F(mathbf {x} _{1})geq F(mathbf {x} _{2})geq cdots ,}

如果顺利的话序列(xn){displaystyle (mathbf {x} _{n})}收敛到期望的极值。注意每次迭代步长γ{displaystyle gamma }可以改变。


右侧的图片示例了这一过程,这里假设F{displaystyle F}定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数F{displaystyle F}为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数F{displaystyle F}值最小的点。
例子
梯度下降法处理一些复杂的非线性函数会出现问题,例如Rosenbrock函數
- f(x,y)=(1−x)2+100(y−x2)2.{displaystyle f(x,y)=(1-x)^{2}+100(y-x^{2})^{2}.quad }

其最小值在(x,y)=(1,1){displaystyle (x,y)=(1,1)}处,数值为f(x,y)=0{displaystyle f(x,y)=0}。但是此函数具有狭窄弯曲的山谷,最小值(x,y)=(1,1){displaystyle (x,y)=(1,1)}就在这些山谷之中,并且谷底很平。优化过程是之字形的向极小值点靠近,速度非常缓慢。


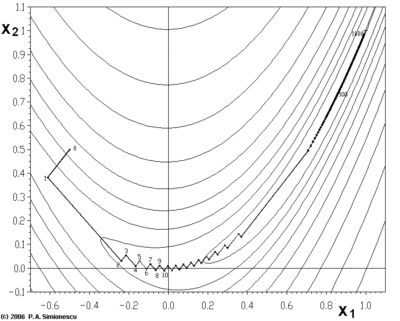
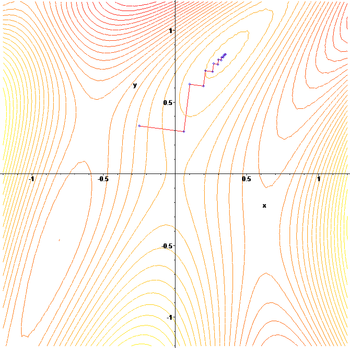
下面这个例子也鲜明的示例了"之字"的上升(非下降),这个例子用梯度上升(非梯度下降)法求F(x,y)=sin(12x2−14y2+3)cos(2x+1−ey){displaystyle F(x,y)=sin left({frac {1}{2}}x^{2}-{frac {1}{4}}y^{2}+3right)cos(2x+1-e^{y})}的极大值(非极小值,实际是局部极大值)。


缺点
梯度下降法的缺點包括:[1]
- 靠近極小值时速度减慢。
- 直線搜索可能會產生一些問題。
- 可能會“之字型”地下降。
上述例子也已体现出了这些缺点。
参阅
|
|
参考文献
^ David W. A. Bourne. Steepest Descent Method. (原始内容存档于2009年2月10日) (英语).
- Mordecai Avriel (2003). Nonlinear Programming: Analysis and Methods. Dover Publishing. ISBN 0-486-43227-0.
- Jan A. Snyman (2005). Practical Mathematical Optimization: An Introduction to Basic Optimization Theory and Classical and New Gradient-Based Algorithms. Springer Publishing. ISBN 0-387-24348-8
外部链接
(英文)Interactive examples of gradient descent and some step size selection methods
(英文)Using gradient descent in C++, Boost, Ublas for linear regression


